Part II – Shifting gears – understanding the potential of LegalTech
Where do we go from here?
A fortuitous aspect of working at D2LT is everyday exposure to hyper-modern solutions to automating capital markets. Hence, it’s comical to note that the technology exploration that I have been involved with that captured me has taken me to a 1970s programming language, Prolog. It was developed and implemented by Alain Colmerauer and Robert Kowalski, building on Robert’s work on the procedural interpretation of Horn clauses.[1] As a fellow “Robert”, I am sure there is just a meeting of great minds in working with Professor Kowalski – but on a genuine note, it has been phenomenal to be able to work with such an influential figure in computer science circles (just look him up on Wikipedia if you need to!).
Prolog is a declarative programming language meaning the programme logic is expressed in terms of relations between facts and rules. Furthermore, it allows facts involving relationships between individuals and rules linking conclusions and conditions to be represented accurately with thankfully no expertise in logical computing or mathematics. Resultant from Prolog, Kowalski has developed a style of natural language termed ‘Logical English’ (“LE”). We can define LE as having a structure that is meant to be:
- Understandable without a computer science background or secondary school mathematics,
- Easily translatable to and executable in Prolog, and
- Unambiguous, to reduce any human misunderstanding or specialist knowledge, and to facilitate computer-executability.
What makes LE exciting is its ability to make the complex ‘legalese’ digestible and understandable to a wide variety of users and make it possible to automate.
Nonetheless, to codify and process the volume of legal documentation an institution would have into LE would be a monumental task at this current moment. Arguably, it would be entirely manual to begin with. However, with further effort and experience, an increasingly routine process is foreseeable. Additionally, LE has no definitive outcome, it is simply trying to achieve a set of goals utilising a declarative writing style – hence there can be differences.
Each institution may have a different system for its agreement drafting going forward; meaning it is difficult for any vendors or consultant to understand the market’s approach as a whole. Hence, a space is open in the market for someone to define a common vocabulary and facilitate a wider use of LE. Furthermore, any attempt to process a back book of agreements would, at first, be extremely manual due to the need to understand the linguistic construction of sentences in order to simplify them. Therefore, as is the case with other machine-orientated computer languages, LE is not the perfect answer on its own and there will need to be trailblazers and product solutions.
A hyper-modern solution – spaCy
Alongside Professor Kowalski, we have also been working with Miguel Calejo – CTO of Logical Contracts – and expert Prolog Developer. Bob (Professor Kowalski’s more informal title) has very much been taking a top-down approach to our review and analysis of master agreement drafting, whereas working with Miguel, we have gone bottom-up, using “spaCy” to assist.
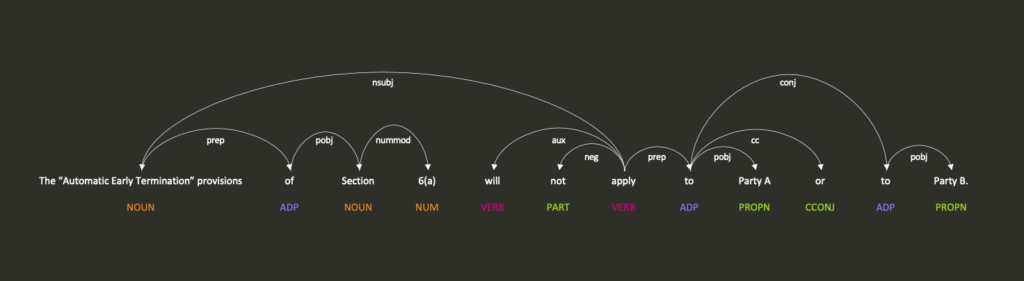
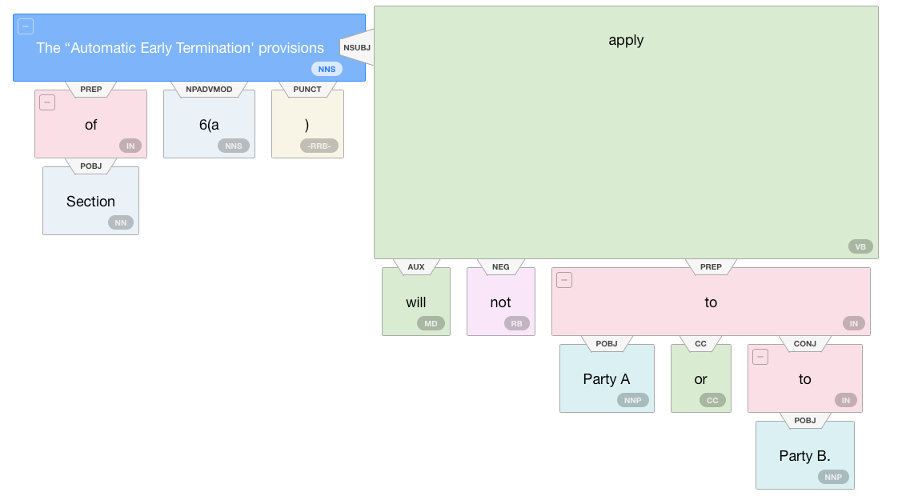
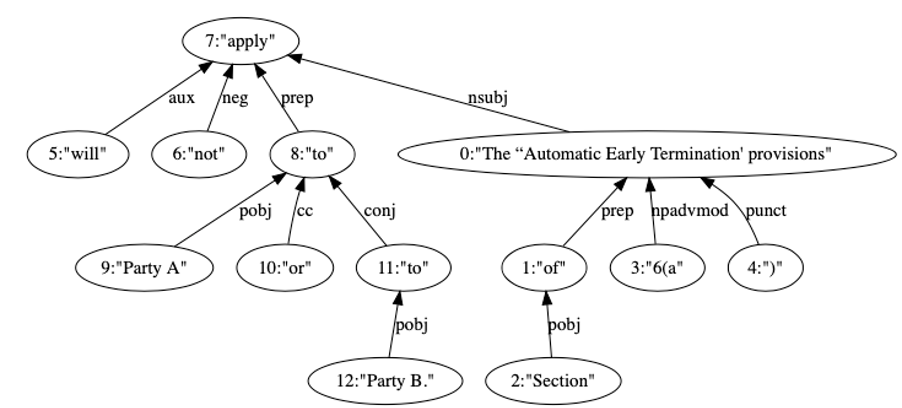
spaCy is a natural language processor. When I began to use it, I felt like I’d finally found a product which lived up to the Matrix. spaCy has an extension, called displaCy, which presents the user with a visual parser tree.[2] spaCy has the ability to provide deep insight into text’s grammatical structure by looking at word types, lemmatisation (roots) of words and syntactic dependencies. Below is an example taken from one of the AET clauses earlier:
displaCy correctly recognises that AET is the noun, or subject, of the sentence. Further it recognises that AET is the object (pobj means the object of a preposition) of Section 6(a) meaning without any further insight we know, at a minimum, Section 6(a) and AET are linked. displaCy then proceeds to recognise that AET is the nominal subject of ‘apply’. This means that ‘apply’ is the syntactic subject of AET, hence we can now understand what is being considered. ‘apply’ is then negated. ‘apply’ then forms part of a preposition (and a conjunction) to Party A and Party B meaning that we understand the subject of the sentence (AET) does not apply to the prepositions, Party A and Party B.
Altering the sentence to the other examples we have given does not impact the first section of analysis surrounding AET’s relations and its place as the subject. Using ‘shall not’ instead of ‘will not’ merely changes the auxiliary verb with no resultant impact. Changing ‘Party A and Party B’ to ‘both parties’ still results in a preposition and evidences it applies to a proper noun as before.
Utilising displaCy in this manner illustrates (rather colourfully) that differences can be broken down in clause variants in such a way which means they are more easily analysed from an NLP perspective because they can be standardised. Clearly, this represents a huge benefit to automation.
Evidently, spaCy is deeply impressive in its power to parse text. However, what is even more impressive is that spaCy has several abilities which could have a compelling influence on legal agreement databases and drafting in the future.
To begin with, spaCy possesses a Named Entity Recognition function which allows ‘real-world’ nouns, such as companies or locations, to be recognised and understood by the programme when analysing sentences. This comes from a maintained database, which, in theory, could be maintained and objectified by every institution to improve their agreements and agreement data.
However, there are limitations. Traditionally, legal text can be considered to have a deontic irrealis mood.[3] As a result, it does not ordinarily have multiple named entities (such as names or places) but will have several entities (text such as ‘Defaulting Party’). This could be problematic when attempting to use spaCy’s Named Entity Recognition as it will require specialist knowledge to produce the correct entities for the function.
Yet, if there was input from subject matter experts in derivatives contracts, we could widen the understanding and produce an industry-wide database for entities such that spaCy could be used more readily to help linguistically understand agreements.
Moreover, spaCy allows for similarity comparisons between documents. Understanding these similarities currently can take a large amount of time and effort. This effort is increased as once differences and similarities have been discovered there will need to be further anlayised. With spaCy this need disappears. Understandably, spaCy requires a huge volume of documents to gain enough understanding of the syntax to accurately compare. This volume of documentation must be accurate. I doubt volume will be an issue, but accuracy may well be.
The ability to quickly and accurately determine how clauses have the same outcome and making it more effortless to construct standardised clauses is extremely important for the future of capital markets. spaCy offers huge potential if the industry can (accurately) get its house in order. This makes the work of firms like D2LT on the ISDA Clause Taxonomy and Library critical. It is firms like this that will ensure we can use this to unlock business value through the legalese.
Additionally, programmes like spaCy (and other parser systems) work most efficiently when the sentences are no more than 70 words. To imagine a sentence close to 70 words in everyday text or speech is (literally) breath-taking. In legal documentation, it is not atypical. By standardising the language and simplifying it using spaCy we will perpetuate spaCy’s improvement.
Finally, spaCy has a wonderful ability to add text classifications to sections of text and then to apply rule-based matching. These two functions will allow a user to find a sequence of text or linguistic annotations which are similar to the original text. The power of this would be to identify in an institution’s back book all similar clauses or sections of text when it implements a standardisation programme. Such an ability removes huge amounts of manual work whilst also improving the quality of an institution’s agreements.
Conclusion
Since starting at D2LT, I’ve been fortunate to gain exposure to the intricate legal side of capital markets and the technological side which surely has to form a large part of the industry’s future. The (multi) million-pound question is how we go about delivering the future.
I’d be foolish to suggest I know the exact answer – but it is clear to see the power of the technology enablers that exist, it’s just we don’t have any agreed legal agreement or data standards to allow us to apply them, allowing us to manage the legal complexity. I can’t help but think this arises due to the lack of time exploring the intersection of technology and the law.
However, products like spaCy and ideas such as LE appear to offer solid grounding on how we go about understanding the task in the first place. Furthermore, it contributes to the fact that there is likely not one solution to the task and different combinations of technology will be required. LegalTech can sometimes be an omniscient term without a direction or meaning; yet, witnessing spaCy and working at D2LT reminds me of the fantastic impact that technology is already having, but more importantly the potential impact it is yet to have.
By Robert Peat
[1] A Horn Clause is a logical disjunction of literals where at most one of the literals is positive. They are a logical formula of a rule and have application in mathematical logic and logic programming.
[2] Parsing presents natural language with its grammatical nature and its syntactic relationship with other words in clauses and sentences.
[3] This simply means that the linguistic expression is what ought to be the situation or action. When writing legal contracts, you are doing exactly this, illustrating what the situation or action should be for either party.